デスク環境のご紹介
こんにちは、@yshr10icです。
デスク環境がそれなりに良い感じになってきたので、
デスク環境に何を使っているのか紹介していきたいと思います。

目次
パソコン
MacBook Pro 13インチ(2020)を使っています。
 - スペースグレイ")
最新モデル Apple MacBook Pro (13インチPro, 16GB RAM, 512GB SSDストレージ, Magic Keyboard) - スペースグレイ
- 発売日: 2020/05/11
- メディア: Personal Computers
また、MacBook Pro 13インチ(2020)には、
wraplusのケースカバーを貼ってシックな見た目にしています。
最近買ったMacBookProのカバーおすすめ!シックでいい感じ。
— yshr_10ic (@yshr_10ic) 2020年7月11日
iPadとかのもあるから、いつか買ったら合わせて買いたいなぁ〜
自分が買ったのはこのネイビーのやつ!https://t.co/9EdpQyVk5j pic.twitter.com/8tKyH5kNvb
![wraplus for MacBook Pro 13 インチ 2020 対応 全31色 [ネイビーブラッシュメタル] スキンシール フィルム ケース カバー](https://m.media-amazon.com/images/I/41eSkrZ7bjL._SL160_.jpg "wraplus for MacBook Pro 13 インチ 2020 対応 全31色 [ネイビーブラッシュメタル] スキンシール フィルム ケース カバー")
MacBook Pro 13インチ(2020)に関しては、以下の記事にも書いています。
ディスプレイ
PHILIPSの23.8型液晶ディスプレイを使っています。
買ったのが2020年4月頃でコロナの真っ只中だったので、
あまり選択肢がなくこれを選びました。
個人的には、32型くらいの4Kのディスプレイが欲しくなってきました。
 23.8型ワイド液晶ディスプレイ ブラック 5年間フル保証 243V7QDAB/11")
Philips(フィリップス) 23.8型ワイド液晶ディスプレイ ブラック 5年間フル保証 243V7QDAB/11
- 発売日: 2017/08/18
- メディア: Personal Computers
ディスプレイに合わせてモニターアームを使っています。
目線が上になるので、モニターアーム買って良かったです。

エレコム PCモニターアーム ディスプレイアーム 回転 ロング ブラック DPA-SL01BK
- 発売日: 2019/05/29
- メディア: Personal Computers
タブレット
 - スペースグレイ")
Apple iPad Air (10.5インチ, Wi-Fi, 64GB) - スペースグレイ
- 発売日: 2019/03/28
- メディア: Personal Computers
マウス
Bluetooth対応で、手にフィットするように少し大きめのマウスにしました。
このマウスは2台まで登録できるので、
MacBook Proと仕事で使っているWindows PCの2台を登録しています。

Digio2 5ボタンBlue LED マウス 無線 Bluetooth 静音 ブラック Z8411
- 発売日: 2019/02/25
- メディア: Personal Computers
キーボード
LogicoolのMX KEYS KX800を使っています。
Bluetooth対応で、WindowsとMacの両方に対応していて、
キーを打った時にカチカチ音がしない
というところに惹かれて買いました。
個人的には、今まで一番気に入っているキーボードです。

- 発売日: 2019/09/27
- メディア: Personal Computers
Logicoolのキーボードが良かったので、
合わせてマウスも欲しくなっている今日この頃です。

- 発売日: 2019/09/27
- メディア: Personal Computers
リストレスト
あんまりしっくりこないので、
たまにしか使っていません。
 MP-095BK")
エレコム マウスパッド リストレスト一体型 疲労低減 "COMFY" ソフト(ブラック) MP-095BK
- 発売日: 2018/06/18
- メディア: Personal Computers
 TOK-MU3NBK")
サンワサプライ キーボード用低反発リストレスト(ブラック) TOK-MU3NBK
- 発売日: 2014/12/01
- メディア: Personal Computers
USBハブ
j5 createのType-C to 3ポートUSB&HDMI マルチハブを使っています。
給電タイプのUSBハブが欲しいので、近々新しいものを買いたいと思います。
JCH451 USB Type-C to 3ポートUSB&HDMI マルチハブjp.j5create.com
ノートPCスタンド
ノートPCスタンドは2種類使用しています。
ノートPCのディスプレイと外付けのディスプレイの
2画面で見たいときは以下を使っています。

エレコム ノートPCスタンド 折りたたみ 8段階 スマホスタンド機能付 ~15.6インチノートPC ブラック PCA-LTS8BK
- 発売日: 2020/02/12
- メディア: エレクトロニクス
ノートPCをクラムシェルモードで使用するときは、
以下を使っています。

WEBカメラ
eMeetのWEBカメラを使っています。
HD1080P、200万画素で画質はそこそこですが、
マイクが2つ付いていたり、
オートフォーカスしたりしてくれるので、
個人的には満足しています。
ビデオ会議をすることができるので便利ですよね。

デスク
山善の電動昇降式デスクを使っています。
![[山善] パソコンデスク (電動昇降式) 幅120cm(奥行70×高さ71-117cm) スタンディングデスク 組立品 ナチュラルウッド/ブラック ELD-FS(MBK)/T1200(WN) 高さ登録可能 在宅勤務](https://m.media-amazon.com/images/I/31n6Zpb4s5L._SL160_.jpg "[山善] パソコンデスク (電動昇降式) 幅120cm(奥行70×高さ71-117cm) スタンディングデスク 組立品 ナチュラルウッド/ブラック ELD-FS(MBK)/T1200(WN) 高さ登録可能 在宅勤務")
- 発売日: 2020/01/23
- メディア: ホーム&キッチン
こちらの電動昇降式デスクに関しては、
過去に記事も書いています。
自動昇降式デスクーーー🎉🎉🎉 pic.twitter.com/dKVB5OE08C
— yshr_10ic (@yshr_10ic) 2020年8月8日
実際の動き pic.twitter.com/y0izGYDI2e
— yshr_10ic (@yshr_10ic) 2020年8月9日
椅子
ニトリのワークチェアを使っています。
可もなく不可もなくという感じです。

今後買いたいもの
まとめ
まだまだ欲しいものはたくさんありますね〜
理想のデスク環境を求めて、これからも少しずつ買い足していきたいです。
電動昇降式デスクを買いました!!!
こんにちは、@yshr10icです。
憧れであった電動昇降式デスクをついに買いました! 本記事では、電動昇降式デスクを買うまでに至った経緯と、組み立て方法について紹介していきたいと思います。
自動昇降式デスクーーー🎉🎉🎉 pic.twitter.com/dKVB5OE08C
— yshr_10ic (@yshr_10ic) 2020年8月8日
目次
買ったもの
私が今回購入した電動昇降式デスクは、山善のものでAmazonで購入しました。価格としては、43,000円ほどだったので、電動昇降式デスクにしては安く済んだのではないかと思っています。
この電動昇降式デスクの特徴としては、以下の通りです。
- 天板の大きさは幅120cm、奥行き70cm
- 高さは71cmから117cmまで1cm刻みで変えることができる
- メモリ機能が搭載されており、好きな高さを4つまで登録することができる
- 耐荷重は80kg
- 衝突検知センサーが搭載されており、昇降中にセンサーが衝撃を感知すると約3センチ戻る仕様
メモリ機能、衝突検知センサーが付いているのは、非常に嬉しいポイントですね!
- 発売日: 2020/01/23
- メディア: ホーム&キッチン
今まで使用していたデスクへの不満
今済んでいる部屋に引っ越してきてから約2年ほど、ニトリのファウラー 80 DBRという机を使用していました。下の画像を見ていただけると分かると思いますが、非常にコンパクトな机となっています。幅80cm、奥行き52cm、高さ72cm(キャスターを使っていなかったので、もう少し低かったです。)
もともと勉強机用に買ったのですが、リモートワークが当たり前になり家で仕事するようになってから、机が狭い、ディスプレイまでの距離が近い、机が低いと非常に悩まされていました。

電動昇降式デスクへの憧れ
普段からブログやYouTubeなどを見ていると、FlexiSpotというメーカーの電動昇降式デスクが紹介されており、非常に憧れていました。ただ、そこそこお値段もするので、なかなか手が出せなかったです。
今まで使用していたデスクへの不満から、幅120cm、奥行き70cmというのが理想でした。しかし、FlexiSpotではこの大きさの天板がなかったので、それも購入に至らなかった理由の一つです。 (FlexiSpotだと幅140cm、奥行き70cmか幅120cm、奥行き60cmでした。)
高さ調節パソコンデスク140*70cmテーブル (脚ブラック天板マホガニー)")
山善の電動昇降式デスクとの出会い
いつか広い部屋に引っ越した際にでも大きめ天板のものを買おうと半ば諦めていたのですが、つい先日Amazonで調べていたら山善の電動昇降式デスクを見つけました。 理想的な幅120cm、奥行き70cmという天板サイズでお値段も4万円ちょっとということで買うことを決意しました!
なお、山善の電動昇降式デスクはカラーによって値段が異なり、一番安いものだと36,000円程度で一番高いものだと53,000円程度になります。カラーにこだわりがないようでしたら、36,000円程度でこの大きさの電動昇降式デスクを購入できるのは、非常にお得だと思います!
- 発売日: 2020/01/23
- メディア: ホーム&キッチン
いざ組み立て
さすがAmazonさん、注文してから2日で届きました。しかも、発送重量43kgなのに送料無料です。うちにはエレベーターもないので配達員の方には申し訳なかったですね。
120cmの天板が入っているので、結構な大きさの段ボールでした。

開けると天板の段ボールが入っています。

続いて、脚部の段ボールです。

脚部の段ボールを開けるとこんな感じになっています。しっかりと梱包されていたので、安心しました。Amazonのレビューで「ネジに不具合があり、予備のネジも入っていなかった」というものがあったので、最初にネジの個数や不具合がないかを確認することをおすすめします。ただ、確認したところすべてのネジが予備で1本多く入っていたので、レビューのときから改善したのだと思われます。

いざ組み立てです。この脚の部分が非常に重いです。

ちょっとずつ組み立てて行きます。

やっと天板をくっつきました。

コントローラーを付けて完成です。基本的な組み立ては六角レンチを使用して取り付けていくのですが、矢印の3つの部品に関しては、プラスドライバーを使用しての取り付けでした。

ひっくり返して、電源に繋いだら完成です。だいたい1時間くらいで組み立てることができました。ネジの取り付けなどは一人で行い、脚や天板を持ち上げたりする作業がある場合には奥さんに手伝ってもらいました。一人ですべて組み立てるのは厳しいです。

動作確認
動画だと音が少し気になりますが、アプリで計測してみたところ40dbくらいでした。個人的には思ったよりも静かだなという印象です。
実際の動き pic.twitter.com/y0izGYDI2e
— yshr_10ic (@yshr_10ic) 2020年8月9日
まとめ
いかがだったでしょうか?今回は山善の電動昇降式デスクについて紹介しました。このブログもスタンディングの状態で書いているのですが、非常に快適です。電動昇降式デスク気になっているけど、高くて手が出せなかった人は、こちらの商品を検討してみてはいかがでしょうか?(デスクとしてはまだまだ高いですが・・・)
- 発売日: 2020/01/23
- メディア: ホーム&キッチン
【Udemy受講メモ】米国AI開発者がゼロから教えるDocker講座
こんにちは、@yshr10icです。
Twitterでフォローさせて頂いているかめさん(@usdatascientist)がUdemyでDockerの入門講座を公開されていたので、受講してみました! 非常に良い講座だったので、受講メモとして残しておきたいと思います。
目次
おすすめポイント
まず最初に、本講座を受講してみておすすめしたい!と思ったポイントを紹介したいと思います。
- 基礎から順序良く
- 重要なことは何度も繰り返す
- 今何をやっているかをスライドで説明
- データサイエンスやWEBアプリ開発で使える方法についても紹介
- 聞き取りやすい声(私は2倍速で聞いていましたが、それでも聞き取りやすかったです)
講座について
次に実際の講座内容に関してのメモです。
準備
Linuxの基礎、Dockerのインストール方法を勉強します。 Linuxの基礎では、「cd」や「ls」などの基本的な操作を確認します。 すでにここら辺の知識のある方は飛ばしても問題ないと思います。
Docker基礎
Dockerをとりあえず触ってみる
Dockerイメージをプルして、コンテナを起動してみたり、 Dockerイメージを作成して、Docker Hubにプッシュしたりします。 また、docker runの動作についてより詳細に確認します。
基本的なDockerのコマンドやdocker runで良く使用されるオプションの意味や動作について理解することができます。
Dockerfileを使用した実行
Dockerfileの基本的な使い方を勉強します。
RUNやCMDなどの命令がどのように動くのかを理解することができます。
個人的に、本講座で一番勉強になったのが、Dockerfileの作り方だと思っています。基本的な使い方を説明した後に、キャッシュやイメージレイヤーの説明があり、実際にDockerfileを書くにはどのような手順を踏んで行けば良いのかを理解することができました。
本講座を受講した後に、個人的にPythonの開発環境をDockerで作ってみようと思い、python dockerfileで検索してみたのですが、以下のようなDockerfileがヒットしました。
... RUN apt-get update RUN apt-get install -y xxx RUN apt-get install -y yyy ...
今までは、ヒットした結果をコピペして使っていたと思いますが、今では、イメージレイヤーが作られてしまうから、&&で繋げた方が良いんだなーということが分かるようになりました。
Docker応用
応用編では、データサイエンス用の環境構築とWebアプリ開発環境の構築を行います。
データサイエンス用の環境構築では、まずローカルでJupyter Labが動く環境を構築します。次にAWSのEC2でインスタンスを作成し、EC2上でJupyter Labが動くようにします。 最後に、AWSのGPUインスタンスを利用して、GPU環境でのDockerfileの作成方法を勉強します。
次にWebアプリ開発環境の構築では、RailsのWebアプリを作成します。 ここでは、Docker composeを使ってRailsとPostgreSQLの2つのコンテナを作成する方法を学びます。 そして、GitHubにソースコードをプッシュしたら、Travis CIがテストを実行し、問題なければHerokuにデプロイする、ということまでできるようになります。
Dockerの講座なので、AWSやTravis CIなどについてはあまり詳しく説明されていませんが、どういった手順で、どんなサービスが必要なのか、ということが理解できるようになっています。
まとめ
本講座のおかげでやっとDockerに入門できたかな、と思っています。 今後は自分に必要な環境を作ってみたり、前に挫折した以下の書籍などを通じて、もっとDockerを使いこなせるようになりたいですね!

MacBook Pro Rの環境構築
こんにちは、@yshr10icです。
MacBook ProでのRおよびRStuidoの環境構築について備忘録として残していきます。
前提条件
- PC:MacBook Pro(13-inch, 2020, Four Thunderbolt 3 ports)
- OS:macOS Catalina(バージョン:10.15.4)
手順
Rのインストール
https://www.r-project.org/の左にあるCRANをクリック。

Japanで検索もしくは下スクロールでJapanの箇所まで移動し、URLをクリック。

Download R for (Mac) OS Xをクリック。

最新のバージョンのファイルをクリック。

ダウンロードが完了したら、そのファイルをダブルクリック。 このあとは指示に従って進めるだけ。







RStudioのインストール
https://rstudio.com/のProducts>RStudioをクリック。

RStudio Desktopをクリック。

DOWNLOAD RSTUDIO DESKTOPをクリック。

下の方にスクロールし、RStudio DesktopのFreeとなっているDOWNLOADをクリック。

DOWNLOAD RSTUDIO FOR MACをクリック。

ダウンロードが完了したら、そのファイルをダブルクリックし、アプリケーションフォルダに移動するだけ。

MacBook Pro Dockerのインストール
こんにちは、@yshr10icです。
MacBook ProでのDockerのインストールについて備忘録として残していきます。
前提条件
- PC:MacBook Pro(13-inch, 2020, Four Thunderbolt 3 ports)
- OS:macOS Catalina(バージョン:10.15.4)
- Docker Hubのアカウントを作成済であること
Dockerのインストール手順
https://hub.docker.com/editions/community/docker-ce-desktop-macから、「Get Docker」を押下。

Docker.dmgをダブルクリックし、Docker.appをアプリケーションフォルダに移動する。

アプリケーションフォルダからDocker.appを起動すると、権限を聞かれるので、OKを押下。

Skip tutorialを押下。

以下の画面が表示されるので、コマンドをコピーする。

ターミナルで以下の画面が出ると、インストールに成功しています。

インストールしたDockerのバージョンは、docker versionで確認できます。

その他の設定
まずはターミナルでログインしておく。docker loginでログインできる。

設定画面の「General」からSend usage statisticsのチェックを外す。
今のところ特にそれ以外設定することがなかったので、Apply & Restartを押下。

参考書籍
今後は以下の書籍でDockerについて勉強を進めて行く予定です!

- 作者:山田 明憲
- 発売日: 2018/08/25
- メディア: 単行本(ソフトカバー)
MacBook Pro anyenvによる環境構築
こんにちは、@yshr10icです。
MacBook Proでのanyenvの環境構築について備忘録として残していきます。
前提条件
- PC:MacBook Pro(13-inch, 2020, Four Thunderbolt 3 ports)
- OS:macOS Catalina(バージョン:10.15.4)
- Homebrew:2.2.17
anyenvとは
anyenvのインストール
$ brew install anyenv $ anyenv --version anyenv 1.1.1
anyenvのセットアップ
$ anyenv init # Load anyenv automatically by adding # the following to ~/.zshrc: eval "$(anyenv init -)" $ touch ~/.zshrc $ vi ~/.zshrc eval "$(anyenv init -)"
ターミナルを再起動すると、以下の警告が表示される。

指示に従ってコマンドを実行する。
anyenv install --init
マニフェストファイルがないので、チェックアウトするか?と聞かれるので、yと打つ。

プラグインのインストール
anyenv updateコマンドでanyenvで入れた**env系の全てをアップデートしてくれるanyenv-updateプラグイン。anyenv gitコマンドでanyenvで入れた**env系の全てのgitコマンドを実行するanyenv-gitプラグイン。
$ mkdir -p $(anyenv root)/plugins $ git clone https://github.com/znz/anyenv-update.git $(anyenv root)/plugins/anyenv-update $ git clone https://github.com/znz/anyenv-git.git $(anyenv root)/plugins/anyenv-git
pyenvおよびPythonのインストール
pyenvのインストールおよびプロファイルのリロード。
$ anyenv install pyenv $ exec $SHELL -l # プロファイルのリロード
pyenvにより、インストールできるPythonのバージョンの確認。
$ pyenv install -l

Pythonのバージョン3.8.3をインストールする。
$ pyenv install 3.8.3 $ anyenv versions

グローバルバージョンの設定。
$ pyenv global 3.8.3 $ anyenv versions

Pythonのバージョン確認。(プロファイルをリロードしないと、バージョンが更新されない。)
$ exec $SHELL -l $ python -V

他の言語をインストールする
Go
pyenvと同様の手順でインストール。

Node.js
pyenvと同様の手順でインストール。

MacBook Pro VSCodeの設定
こんにちは、@yshr10icです。
MacBook ProでのVSCodeの設定について備忘録として残していきます。
前提条件
- PC:MacBook Pro(13-inch, 2020, Four Thunderbolt 3 ports)
- OS:macOS Catalina(バージョン:10.15.4)
Visual Studio Code(VSCode)
VSCodeは以下からダウンロードします。
拡張機能の追加
拡張機能を入れる前のデフォルトはこんな感じです。

Japanese Language Pack for Visual Studio Code
VSCodeを日本語化。

vscode-icons
ファイル名の横にアイコンを表示する。
![]()
Prettier
コードの自動フォーマッタ。
Bracket Pair Colorizer 2
()や{}などのカッコを色別に表示してくれる。
以前はBracket Pair Colorizerを使用していたが、最終更新日が2019/7/16となっていたので、新しいバージョンの方をインストール。

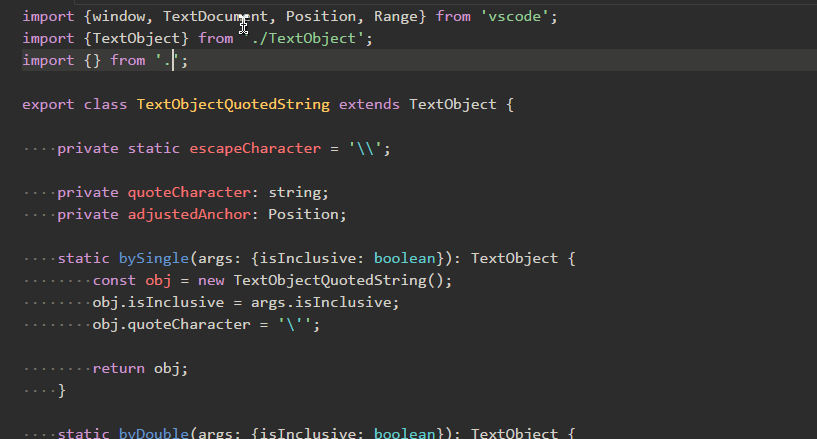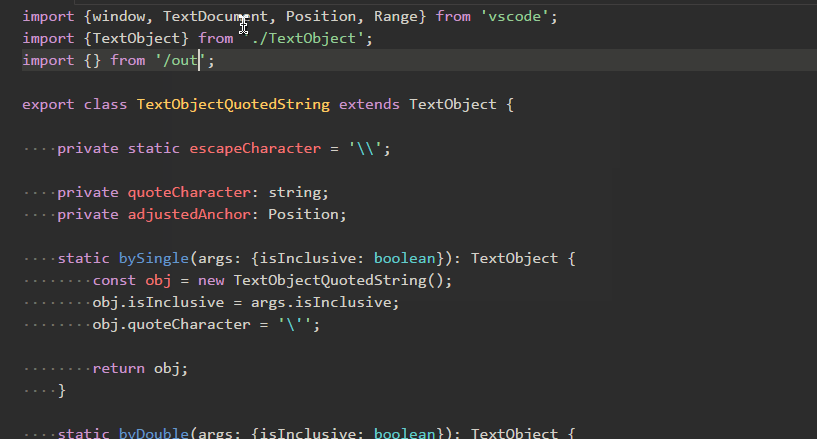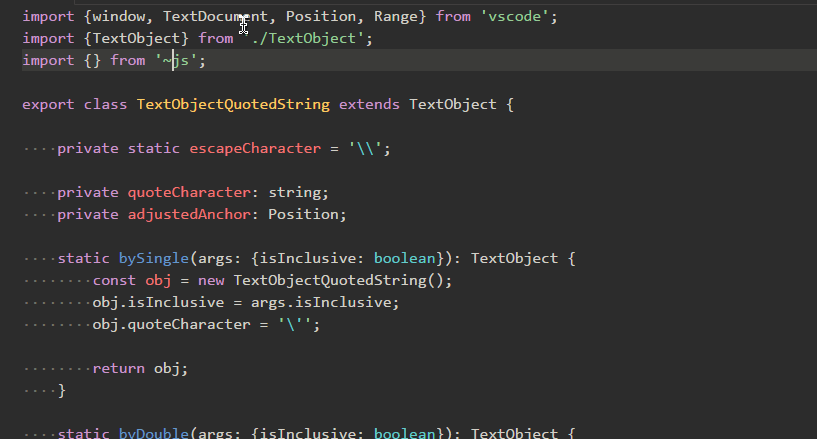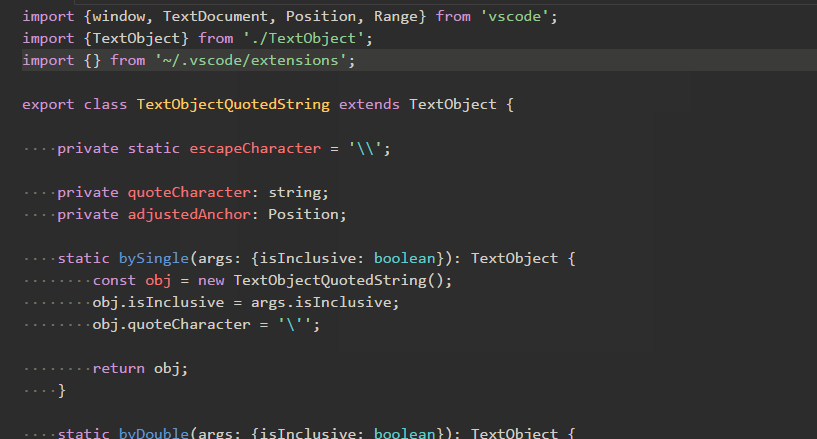
Path Autocomplete
パスの自動入力。
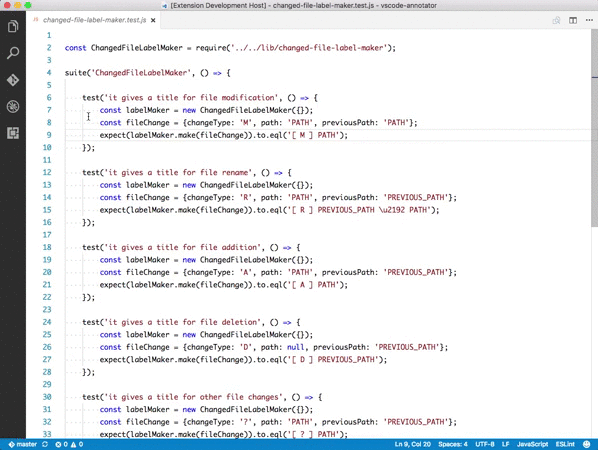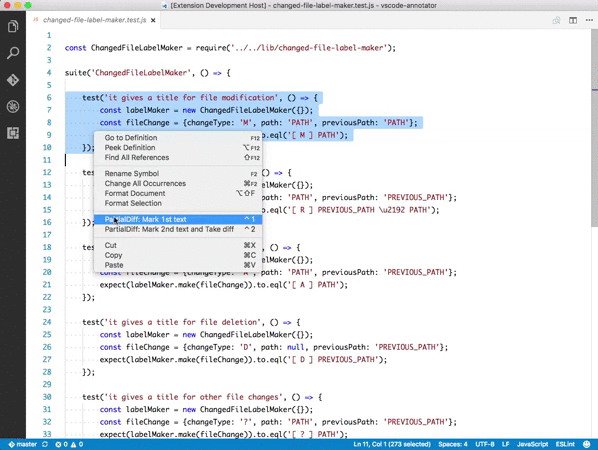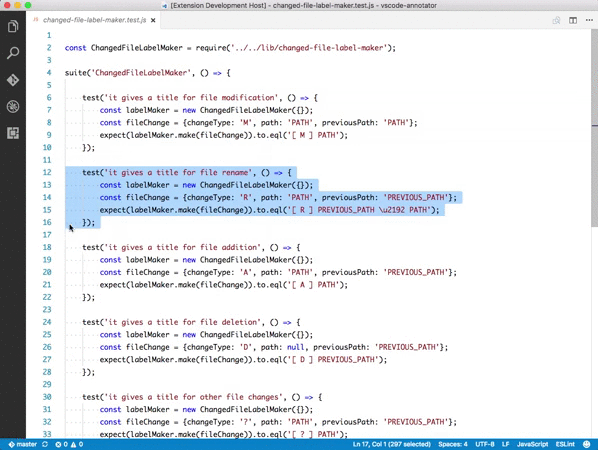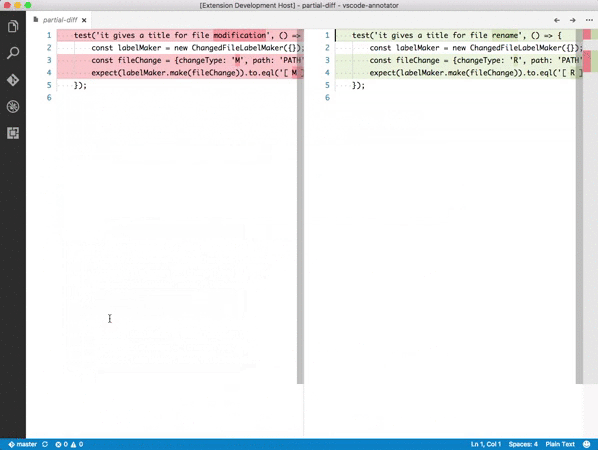
Partial Diff
選択した部分の差分を確認できるプラグイン。
Rainbow CSV

TODO Highlight
TODOなどのコメントにハイライトを設定できるプラグイン。

Trailing Spaces
Regex Previewer

SQLTools
DBクライアント。
GitLens
git blameをVScodeで使えるようにしたもの。ちなみにblameコマンドは特定の行がいつ誰のコミットによって変更されたのかを確認するコマンド。
Git History
Python
Pythonのインテリセンスやデバッガなどの機能を入れてくれるプラグイン。
codeコマンドのインストール
VSCodeはターミナルで、codeコマンドを実行すると、VSCodeを開くことができますが、デフォルトだとCommand not foundとなります。

VSCodeを開いて、Command + Shift + pでコマンドパレットを開きます。そこで、Shell Command: Install 'code' command in PATHを選択します。

Shell command 'code' successfully installed in PATH.とポップアップが出るので、あとはターミナルからcodeコマンドが使用できるようになります。